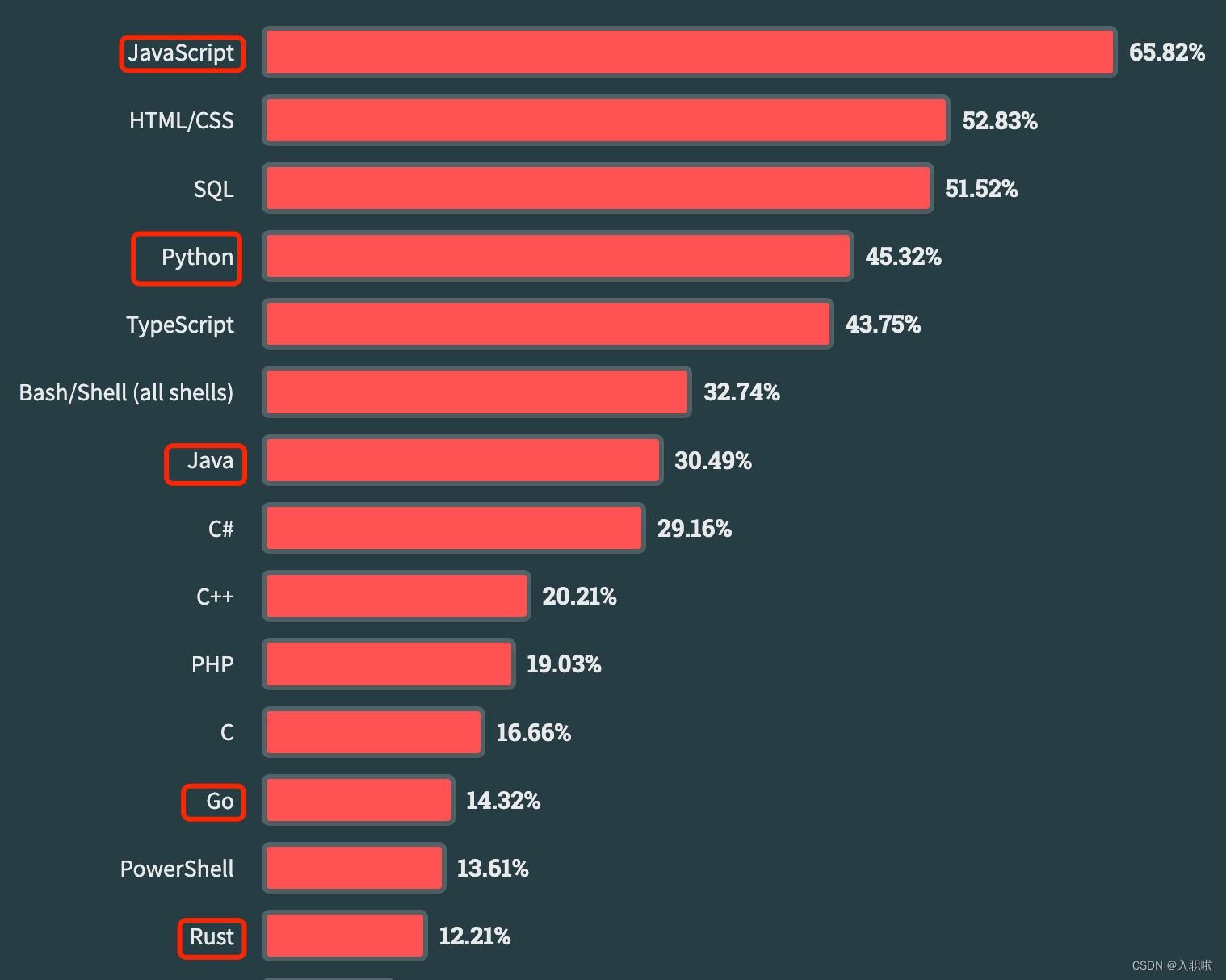
想要获取那些用JavaScript加密的网页内容吗?通常,常规的爬虫技术可能达不到目的。但Python却能提供多种有效的解决方案。今天,我们将深入探讨如何使用Selenium进行数据采集,并且还会介绍一些实用的技巧。
爬取难题与Selenium登场
在互联网行业,JS加密技术给爬虫设置了重重关卡,导致爬虫难以直接获取网页信息,给数据收集带来了不少困扰。在这种情形下,Selenium工具显得尤为关键。Selenium原本用于自动化测试,它能够模仿用户在浏览器中的操作,对于需要JS渲染的网页来说,它尤其适用,可以说是解决这类问题的得力助手。
Selenium使用简单,只需在Python中安装相应库,配置好浏览器驱动即可开始使用。网上有大量可供参考的代码资源,即便是初学者也能迅速掌握。此外,它模拟的是真实用户行为,不易被网站的反爬虫机制识别。
pip install selenium
Selenium基本爬取示例
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
设置ChromeDriver路径
chrome_driver_path = 'path/to/chromedriver'
service = Service(chrome_driver_path)
初始化Chrome浏览器
driver = webdriver.Chrome(service=service)
打开目标网页
driver.get('https://example.com')
等待页面加载完成
driver.implicitly_wait(10)
获取页面内容
content = driver.page_source
关闭浏览器
driver.quit()
print(content)
了解Selenium抓取网页的基本步骤是必要的。到了2024年,众多网站开始采用JavaScript对信息进行加密。例如,一些新闻网站的部分内容就是通过JavaScript动态加载的。因此,首先需要在Python中安装Selenium库,并配置好浏览器驱动,例如ChromeDriver。编写代码时,需导入必要的模块,接着创建driver实例,并通过get方法打开网页,从而获取页面源码或解析页面元素。
操作时,先变更网页链接为你要爬取的目标网址,接着提取网页核心内容。此外,众多开源项目已提供详尽的Selenium爬取脚本,你可以按需调整,以便高效完成爬取工作。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
打开目标网页
driver.get('https://example.com')
等待特定元素加载完成
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'element_id'))
)
获取页面内容
content = driver.page_source
pip install pyppeteer
等待JS加载及处理动态内容
网页上经常展示活动信息,但要准确获取这些信息,必须等待JavaScript完成加载。这时,我们可以运用WebDriverWait来实现对元素的显式等待。以某新闻网站为例,某些文章的阅读量数据会经历一个延迟加载的过程。我们可以设定一个等待时间以及判断标准,确保元素完全加载后再执行后续操作。
import asyncio
from pyppeteer import launch
async def main():
# 启动浏览器
browser = await launch()
page = await browser.newPage()
# 打开目标网页
await page.goto('https://example.com')
# 等待页面加载完成
await page.waitForSelector('#element_id')
# 获取页面内容
content = await page.content()
# 关闭浏览器
await browser.close()
print(content)
运行异步主函数
asyncio.get_event_loop().run_until_complete(main())
在操作过程中,合理调整等待时间至关重要。若等待时间过长,效率会受到影响;若时间过短,则可能造成数据缺失。针对加载较慢的页面,可以适当延长等待时间,或者启用重试机制,以确保数据的完整性。
Pyppeteer爬取网页示例
除了Selenium,Pyppeteer也是网页抓取的得力助手。这个工具完全是用Python语言编写的,并且没有界面。Pyppeteer的一个显著优点是它可以在后台默默运行,不需要显示界面,从而减少了系统资源的消耗。对于需要抓取大量数据的任务,这一点尤为关键。以抓取新闻网站数据为例,我们首先需要在Python环境中安装Pyppeteer库。
import requests
构造请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
构造请求参数(假设已经解密)
params = {
'param1': 'value1',
'param2': 'value2'
}
发送请求
response = requests.get('https://example.com/api', headers=headers, params=params)
print(response.text)
编写代码时,我们得先构建一个浏览器模型,再开启一个新窗口。利用goto命令,我们能浏览到特定的网页。这样做之后,我们就能捕获页面的元素和相关信息。此外,这一功能还允许我们与网页进行交互,比如点击按钮、填写表格等,这对我们获取最新数据很有帮助。
逆向工程解密加密参数
针对那些用JavaScript加密的复杂网页,我们一般需要通过逆向工程来揭示其内部的参数。这可以通过使用浏览器自带的开发者工具(如F12键)来实现。借助这些工具,我们可以监控网页的网络行为,并找出在JavaScript加密过程中至关重要的请求和参数。以某电商网站为例,商品价格在加密后,会通过特定的算法进行数据传输。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
设置ChromeDriver路径
chrome_driver_path = 'path/to/chromedriver'
service = Service(chrome_driver_path)
初始化Chrome浏览器
driver = webdriver.Chrome(service=service)
打开目标网页
driver.get('https://example.com')
等待页面加载完成
driver.implicitly_wait(10)
获取关键参数
param1 = driver.find_element_by_id('param1').get_attribute('value')
param2 = driver.find_element_by_id('param2').get_attribute('value')
关闭浏览器
driver.quit()
研究加密的基本原理,我利用Python编写了相应的解码工具,并通过模拟浏览器行为来搜集数据。然而,逆向工程的技术门槛不低,它要求掌握JavaScript、算法和加密解密等相关知识。只要精通这些技能,面对爬取信息中的各种挑战,就能轻松应对。
import asyncio
from pyppeteer import launch
async def main():
# 启动浏览器
browser = await launch()
page = await browser.newPage()
# 打开目标网页
await page.goto('https://example.com/api', {
'param1': param1,
'param2': param2
})
# 等待页面加载完成
await page.waitForSelector('#result')
# 获取页面内容
content = await page.content()
# 关闭浏览器
await browser.close()
print(content)
运行异步主函数
asyncio.get_event_loop().run_until_complete(main())
爬取注意事项及技巧
在爬取采用JavaScript加密的网页时,有几个要点需要注意。若网站要求先登录,比如某些社交平台或付费论坛,我们可以通过Selenium或Pyppeteer等工具来模拟登录过程,输入用户名和密码,或者扫描二维码完成登录。登录成功后,就可以开始进行爬取了。同时,在编写代码时,要保证代码的易读性和可维护性,尤其是对于结构较为复杂的网页,代码量可能会比较大,因此做好注释和模块的划分显得尤为重要。
请留意规避网站被封的潜在风险,可以通过更换代理IP地址、调整访问时间等方法,模仿普通用户的行为,减少被误判为爬虫的可能性。例如,调整每次请求之间的时间差,并利用付费代理IP服务确保IP地址的持续可用。
尝试获取加密的JavaScript网页内容时,大家通常觉得哪种方式更得心应手?若这篇文章给您带来了一些帮助,不妨点个赞或推荐给朋友。